
What’s Rnn? Recurrent Neural Networks Defined
The strengths of GRUs lie of their ability to seize dependencies in sequential data efficiently, making them well-suited for tasks the place computational resources are a constraint. GRUs have demonstrated success in varied functions, together with natural language processing, speech recognition, and time sequence types of rnn analysis. They are especially useful in scenarios the place real-time processing or low-latency functions are important as a end result of their faster training instances and simplified structure.
Be Taught Extra About Webengage Privacy
The whole loss for a sequence of x values and its corresponding y values is obtained by summing up the losses over all time steps. Additional saved states and the storage under direct management by the network could be added to each infinite-impulse and finite-impulse networks. Another community or graph can also replace the storage if that includes time delays or has feedback loops.
Problem In Capturing Long-term Dependencies
Such linguistic dependencies are customary in a quantity of text prediction duties. But, what do you do if patterns in your information change with time and sequential data comes into play? These have the ability to remember what it has realized up to now and apply it in future predictions. Where U is like a transition matrix and f is a few nonlinear operate (e.g., tanh). 8(b) that it is potential to make use of the same transition function f with the same parameters (i.e. W, U and V) at every time step.
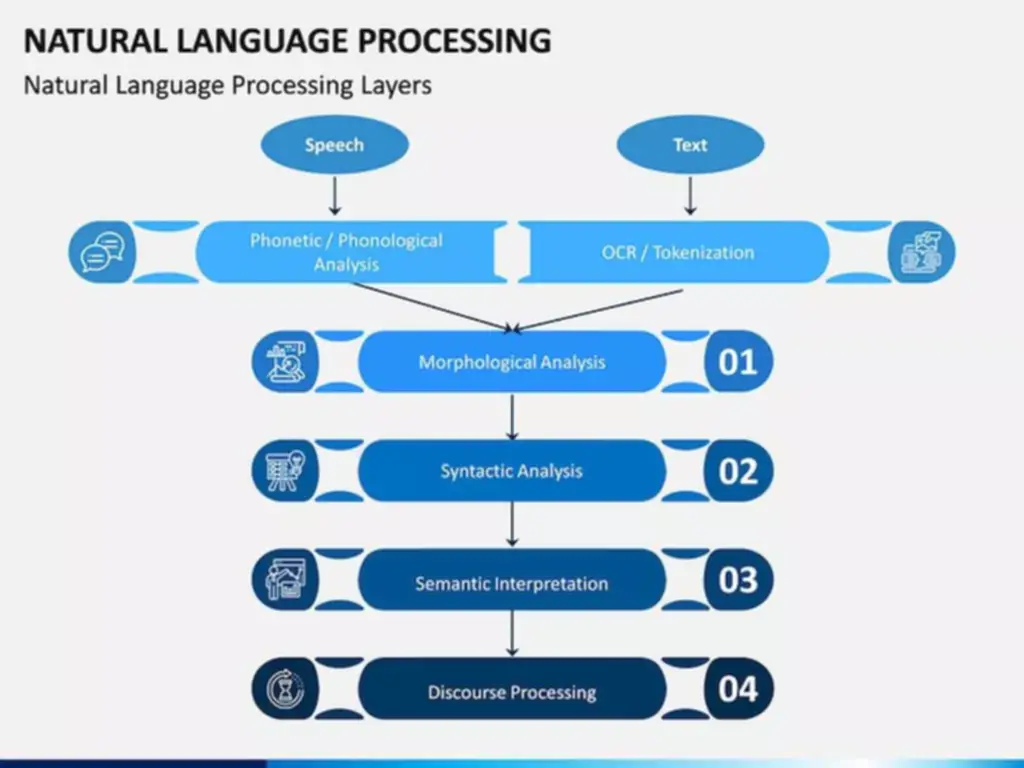
Capacity To Deal With Variable-length Sequences

They work especially nicely for jobs requiring sequences, similar to time sequence information, voice, pure language, and different actions. The key characteristic of an RNN is that the community has suggestions connections, unlike a conventional feedforward neural community. This suggestions loop permits the RNN to mannequin the effects of the sooner components of the sequence on the later a part of the sequence, which is a very important function in relation to modeling sequences [4]. The data in recurrent neural networks cycles by way of a loop to the middle hidden layer.
We create a new instance of our mannequin each time we wish to process a model new sequence. By dividing the lifetime of the network instance into discrete time steps, we will take into consideration networks that contain recurrent layers. Feedforward hyperlinks reflect information flow from one neuron to another by which the info being moved from the current time step is the calculated neuronal activation. However, recurrent connections constitute info circulate by which the data is the saved neuronal activation from the preceding time step. Therefore, neuron activations in a recurrent community reflect the community instance’s accumulating state.
This is as a result of the network has to course of each enter in sequence, which could be sluggish. RNNs course of enter sequences sequentially, which makes them computationally environment friendly and straightforward to parallelize. An exemplary LSTM network structure, where the reminiscence cells are linked in a cascaded form (x and h are the input and the output, respectively). Prepare knowledge and construct fashions on any cloud using open source frameworks corresponding to PyTorch, TensorFlow and scikit-learn, instruments like Jupyter Notebook, JupyterLab and CLIs or languages such as Python, R and Scala. Because of its less complicated structure, GRUs are computationally more environment friendly and require fewer parameters in comparison with LSTMs.

A suggestions loop is created by passing the hidden state from one time step to the next. The hidden state acts as a memory that shops information about previous inputs. At each time step, the RNN processes the present enter (for example, a word in a sentence) together with the hidden state from the earlier time step. This allows the RNN to “remember” earlier knowledge factors and use that info to affect the current output. An RNN may be used to predict every day flood ranges based mostly on previous daily flood, tide and meteorological knowledge.
Image-to-text translation models are expected to convert visible information (i.e., images) into textual data (i.e., words). In common, the image input is passed via some convolutional layers to generate a dense representation of the visual data. Then, the embedded representation of the visible data is fed to an RNN to generate a sequence of textual content. RNN idea was first proposed by Rumelhart et al. [1] in a letter revealed by Nature in 1986 to describe a new learning procedure with a self-organizing neural community. The Hopfield network [2] is totally related, so each neuron’s output is an input to all the opposite neurons, and updating of nodes occurs in a binary method (0/1).
Ultimately, the selection of LSTM architecture ought to align with the project requirements, data characteristics, and computational constraints. As the sphere of deep learning continues to evolve, ongoing research and advancements may introduce new LSTM architectures, additional increasing the toolkit obtainable for tackling various challenges in sequential knowledge processing. In a regular RNN, one input is processed at a time, leading to a single output. In contrast, throughout backpropagation, both the current input and former inputs are used.
The authors noted that, growing the layer of deep RNN will significantly enhance computational time and memory usage and suggest a three-layer architecture for optimal performance. To scale back reminiscence utilization, (Edel & Köppe, 2016) developed optimised binary version of Bidirectional LSTM for human exercise recognition in a resource constrained environment corresponding to mobile or wearable gadgets. The extended model of Bidirectional LSTM (Graves & Schmidhuber, 2005) achieved real-time and online exercise recognition by making use of binary values to the network weight and activation parameters. The deep-RNN network is a multi-layer perceptron with multiple hidden layers. It combines low-level options to type more summary high-level illustration attribute classes or features to discover distributed feature representations of information.
This research used a deep neural community for the estimation of blood stress. These neural networks have been efficiently implemented and achieved significant leads to speech recognition (Sak, Senior, & Beaufays, 2014) and handwriting (Graves et al., 2008). Long Short-Term Memory (LSTM) (Hochreiter & Schmidhuber, 1997) has been used on this research as a end result of it has the aptitude to study long-term dependencies. They educated a single recurrent neural community for each person’s information to attain high-quality results. This study claimed a robust method for a remote health monitoring system that didn’t require a conventional blood stress methodology.
- Unlike recurrent neural networks, feed-forward networks lack memory and struggle with predicting future events.
- This structure is particularly highly effective in natural language processing tasks, such as machine translation and sentiment evaluation, where the context of a word or phrase in a sentence is essential for accurate predictions.
- RNNs are a kind of neural community that can be used to model sequence knowledge.
- Transformers can seize long-range dependencies rather more effectively, are simpler to parallelize and carry out higher on tasks similar to NLP, speech recognition and time-series forecasting.
In LSTM, the computation time is large as there are plenty of parameters concerned throughout back-propagation. To cut back the computation time, gated recurrent unit (GRU) was proposed within the 12 months 2014 by Cho et al. with much less gates than in LSTM [8]. The functionality of the GRU is much like that of LSTM however with a modified structure. Like LSTM, GRU additionally solves the vanishing and exploding gradient downside by capturing the long-term dependencies with the assistance of gating models. The reset gate determines how a lot of the previous data it must forget, and the replace gate determines how a lot of the past information it wants to hold ahead.

This makes it difficult for the network to study long-term dependencies in sequences, as data from earlier time steps can fade away. Standard LSTMs, with their reminiscence cells and gating mechanisms, serve as the foundational architecture for capturing long-term dependencies. BiLSTMs enhance this capability by processing sequences bidirectionally, enabling a more complete understanding of context.
Vanishing/exploding gradient The vanishing and exploding gradient phenomena are often encountered within the context of RNNs. The cause why they occur is that it is difficult to seize long term dependencies due to multiplicative gradient that can be exponentially decreasing/increasing with respect to the number of layers. Many-to-One is used when a single output is required from multiple enter items or a sequence of them.
Transform Your Business With AI Software Development Solutions https://www.globalcloudteam.com/